GPU modified Toeplitz hashing#
See also
The full source code of this example is in examples/validation_gpu_modified_toeplitz_zeromq.py

A photo of an old Nvidia GeForce3 Ti 500 (source: Wikipedia.org)#
{kind=link}
Modern GPUs can be used to accelerate many computation tasks. Primitive graphics accelerators were developed quite early to unburden the CPU from some computations. However, in the early 2000s, both Nvidia (with their GeForce 3 Series) and ATI (with their Radeon R300) moved to the direction of the so called general purpose GPUs (GPGPUs). These cards supported some mathematical functions and loops. Multiple languages and interfaces were developed to support accelerating devices and GPUs in particular (e.g., OpenCL, CUDA, OpenACC, …). Nowadays, GPUs from Nvidia, AMD and Intel have evolved to become even more general-purpose parallel processors, and they are widely use to to accelerate many computations in different fields. In this particular example, the GPU is used to accelerate the FFT computation.
Nico Bosshard implemented the modified Toeplitz hashing to run on GPUs using the CUDA library for supported Nvidia cards and with Vulkan for many other compatible GPUs (AMD, Intel, etc.). This implementation [12] is open source and it is available on GitHub. To the best of our knowledge, this remains the fastest modified Toeplitz implementation, and for that reason it has been used in at least one QKD experiment [13], where the privacy amplification step could not be implemented with FPGAs for the required block lengths and throughput.
Here we briefly explain the setup we used to test this implementation, and show how the CUDA version was validated
with the Validator class using input_method="custom" and a custom implementation of
ValidatorCustomClassAbs that takes advantage of ZeroMQ to exchange the arrays between our reference
implementation and the CUDA application.
PrivacyAmplificationCuda#
The PrivacyAmplificationCuda application was compiled using CUDA 12.3.1 and executed on a
NVIDIA GeForce GTX 1070. The following config.yaml was used instead of the upstream one:
factor_exp: 27
reuse_seed_amount: 0
vertical_len: 50331648
do_xor_key_rest: true
do_compress: true
reduction_exp: 11
pre_mul_reduction_exp: 5
gpu_device_id_to_use: 0
input_blocks_to_cache: 16
output_blocks_to_cache: 16
show_ampout: 8
show_zeromq_status: true
use_matrix_seed_server: true
address_seed_in: 'tcp://<REDACTED>:45555'
use_key_server: true
address_key_in: 'tcp://<REDACTED>:47777'
host_ampout_server: true
address_amp_out: 'tcp://*:48888'
store_first_ampouts_in_file: 0
verify_ampout: false
verify_ampout_threads: 8
This configuration chooses a particular family of modified Toeplitz hashing
functions that takes \(2^{27} + 1\) bits (\(\sim 17\) MB) as input and outputs 50331648 bits (\(\sim 6\) MB).
This family requires \(2^{27}\) uniform bits as seed to select one particular hash function. Relevant to run this
particular validation are the parameters address_seed_in, address_key_in and address_amp_out. The first two
are the addresses where the application will try to pull the extractor input and seed, respectively,
using ZeroMQ sockets. The last is the address where the output of the extractor will be pushed. To read a full
description of all the paramenters in the configuration file, check the commented version upstream.
Note
The IP of the server where randextract was running was redacted. If you try to replicate this experiment,
change the address_seed_in and address_seed_in with a valid IP. If you are running our Python package in
the same device as PrivacyAmplificationCuda, try using the host loopback address 127.0.0.1.
Validator with custom class#
Our Validator class supports the input_mode="custom" to allow the user to validate implementations that do
not use standard input and output, or files, to obtain the extractor inputs and seeds and to save the output. In this
particular case, all the arrays are communicated as raw bytes using ZeroMQ sockets in a push/pull pipeline pattern.
In this mode, the Validator also expects a custom_class, which is an instance of an implementation class of
the base abstract class provided in ValidatorCustomClassAbs. The implementation class should contain, at least,
the following three methods: get_extractor_inputs(), get_extractor_seeds() and get_extractor_output().
This is enforced by the abstract class, raising a TypeError if some of these are missing. The first two methods
should produce generators (i.e., yield instead of return). This is implementation class used to test
PrivacyAmplificationCuda.
class CustomValidatorGPU(ValidatorCustomClassAbs):
def __init__(self, extractor):
self.ext = extractor
self.count = 0
def get_extractor_inputs(self):
with zmq.Context() as ctx:
with ctx.socket(zmq.PUSH) as s:
s.set_hwm(1)
s.bind(ADDRESS_INPUT)
while self.count < SAMPLE_SIZE:
ext_input = GF2.Random(self.ext.input_length, seed=RNG)
# If patch https://github.com/nicoboss/PrivacyAmplification/pull/2 is not applied
# ext_input[-1] = 0
input_bytes = gf2_to_bytes(ext_input, "little")[
: math.ceil(INPUT_LENGTH / 32) * 4
]
# Flags required by the Cuda implementation to apply the correct
# Modified Toeplitz hashing. See SendKeysExample for more details
s.send(b"\x01", zmq.SNDMORE)
s.send(b"\x01", zmq.SNDMORE)
s.send(np.uint32(OUTPUT_LENGTH // 32).tobytes(), zmq.SNDMORE)
s.send(input_bytes, 0)
yield ext_input
self.count += 1
return
def get_extractor_seeds(self):
with zmq.Context() as ctx:
with ctx.socket(zmq.PUSH) as s:
s.set_hwm(1)
s.bind(ADDRESS_SEED)
while self.count < SAMPLE_SIZE:
ext_seed = GF2.Random(self.ext.seed_length, seed=RNG)
seed_bytes = gf2_to_bytes(ext_seed, "little")[:INPUT_LENGTH]
# Flags required by the Cuda implementation to apply the correct
# Modified Toeplitz hashing. See SendKeysExample for more details
s.send(b"\x00\x00\x00\x00", zmq.SNDMORE)
s.send(seed_bytes, 0)
yield ext_seed
return
def get_extractor_output(self, ext_input, ext_seed):
with zmq.Context() as ctx:
with ctx.socket(zmq.PULL) as s:
s.set_hwm(1)
s.connect(ADDRESS_OUTPUT)
recv_output = s.recv()
gpu_output = bytes_to_gf2(recv_output, mode="big")
return gpu_output
Notice the following:
The constructor (
def __init__()) is optional, but here it is used to keep a counter and implement something similar to what is done by theValidatorclass when used withinput_method="stdio"and the kwargsample_size. It also takes an extractor as input to have access to its propertiesinput_lengthandseed_length.All the communication with the CUDA application in the
get_extractor_inputs()andget_extractor_seeds()methods is done before yielding the randomly generated arrays. This ensures thatget_extractor_output()will never be called before the GPU implementation has received the two inputs.Two functions are used to convert between GF2 arrays and memory buffers (raw bytes). These are defined in the example script and, therefore, not shown above. Alternatively, if you prefer your custom class to be self-sufficient, they could be added as static methods.
As mentioned in a code comment, if this patch is not applied, then the last bit of the input passed to the randomness extractor should always be zero to obtain the same results with our implementation. This is due to a bug in the GPU implementation previously unnoticed.
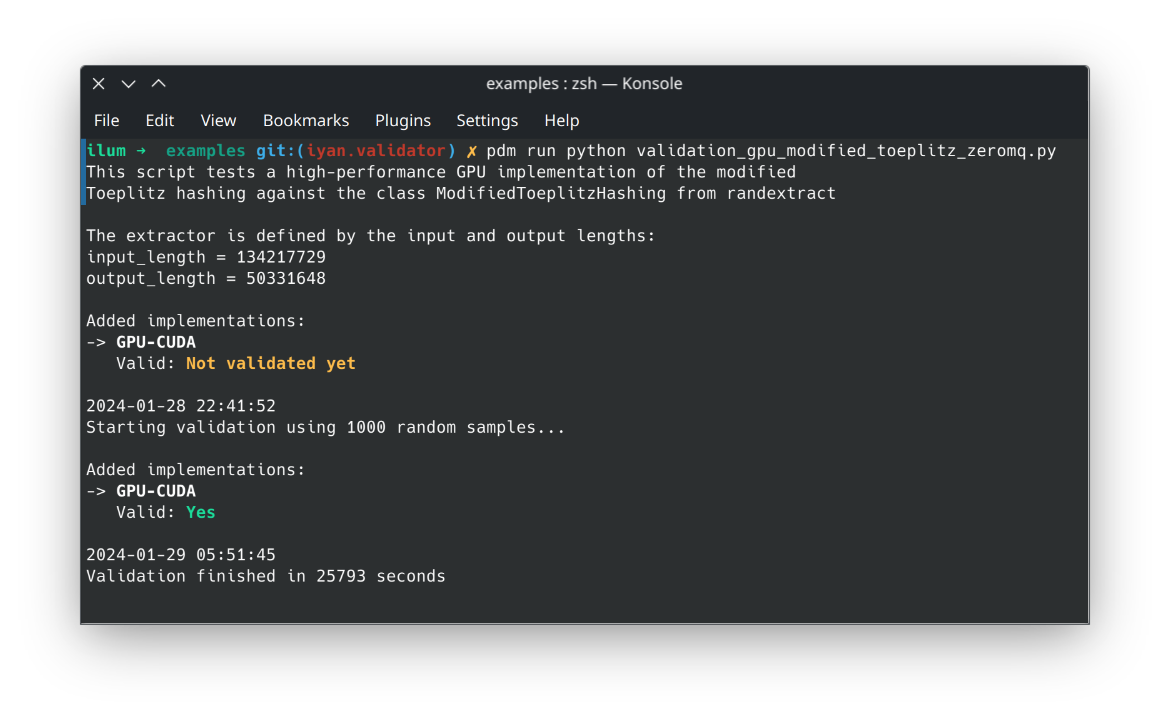
Screenshot after running this example#